How do you extract text from image files? Many of us, at some point, have had the need to use text recognition or optical character recognition (OCR) software in our professional careers. Remember the first time you asked yourself: “How can I extract text from an image?” Well, that was your first call for an OCR tool. You can extract text from an image online as well as offline, but the offline tools are generally more reliable, not to mention safer from a confidentiality and security standpoint.
This article showcases 10 of the best OCR software utilities on the market for you to extract text from PDF images or image files. If you’ve been hunting around for ways to extract text from an image or a PDF image file, your search ends here. So, without further ado, here are the Top 10 OCR Software Tools to Edit and Extract Text from Image Files and PDFs.
#1 – PDFelement Pro
PDFelement Pro is a professional PDF editor with advanced functions for OCR, batch processing, data extraction, OCR directly from a scanner input, and other business-critical tasks to let you extract text from image files and PDF images. The functions are as comprehensive as the pricing is competitive, and it is the ideal tool for any small business or large enterprise because of its scalability and ease-of-use. No more wondering, “How can I extract text from an image” when you have this amazingly accurate tool at your disposal.
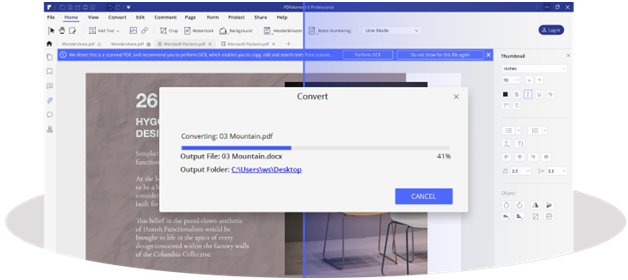
The OCR function allows users to directly edit scanned PDFs by converting them into an editable format. You can also convert image files or image-based PDF files into searchable files for archiving purposes. The ‘extract data’ feature of PDFelement’s OCR plugin allows you to select a specific area to get data from. You can also perform OCR on a large batch of files to save time and make you more efficient and productive.
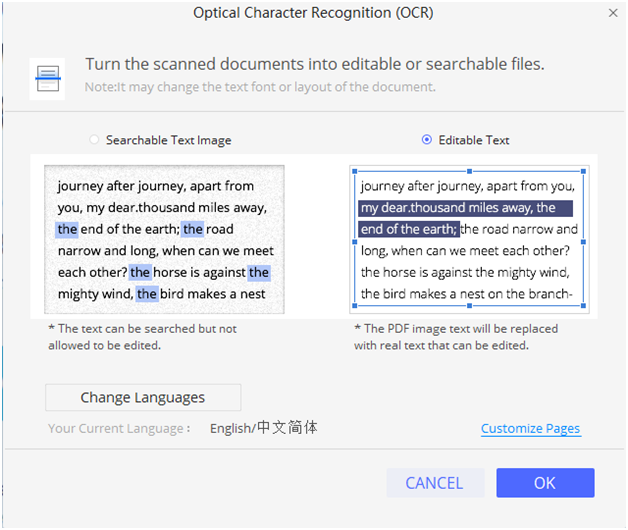
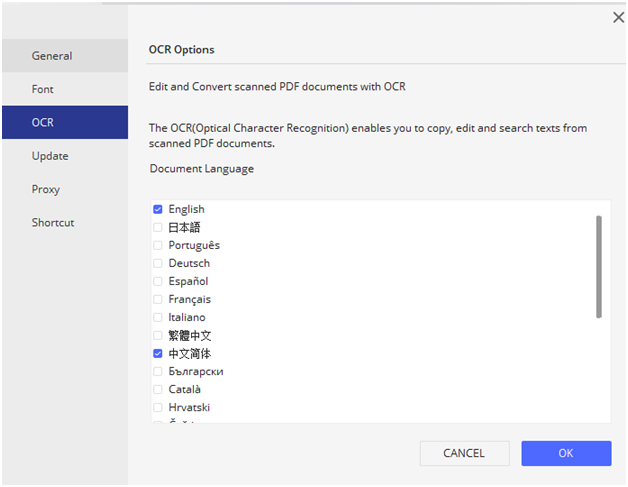
If you are not from English country, PDFelement provide more than 20 languages to help your productivity without worry. Such as English, Portuguese, Japanese, Spanish, German, Italian, French, Bulgarian, Chinese Simplified, Chinese Traditional, Croatian, Catalan, and more languages.
In short, PDFelement Pro and its OCR function give you the freedom to do what you need to with your document workflows, including editing, conversion, security, organizing, form-handling, printing, and sharing.
Special Offer: Get a 7-day free trial with every subscription to the PDFelement newsletter.
#2 – Rossum
This is more of a specialized to extract data from scanned physical invoices and import them into other applications for various purposes. The AI-driven analysis engine lets users put through different invoice types without worrying about how to extract text from image files or PDFs that invoices are usually archived in. The accuracy is very high, estimated by some at around 99%.
While this niche software serves a very specific purpose, you can’t use it to edit PDFs or do anything other than extract specific text and data so you can use that information in other utilities. Although it is limited in this manner, it is well worth the money if you have a large number of paper invoices and bills from suppliers, contractors, vendors, and other third-party stakeholders.
#3 – Readiris
Yet another enterprise-grade OCR software utility is Readiris. There’s very little that this software can’t do. It can virtually extract text from image elements in your documents, and this includes signatures and more. It also works with a lot of other file formats in addition to PDFs. The interface is highly intuitive and there are ready-made help tools if you get stuck.
Language support is amazing – 138 languages and counting – and Readiris is said to be one of the fastest batch tools for OCR. Whether you need to extract text from a PDF image, a JPG, or a scanned document, Readiris has your back. Of course, if you want the whole package with bells and whistles, you’ll need to fork out a couple of hundred dollars, but even the basic version is fairly impressive and will get the job done.
#4 – ABBYY FineReader
The FineReader OCR tool from ABBYY actually powers a lot of other OCR tools and is one of the most accurate on the market. It’s not as affordable as some other options but you’ll find that the price is well justified once you start using the software for OCR and other PDF requirements.
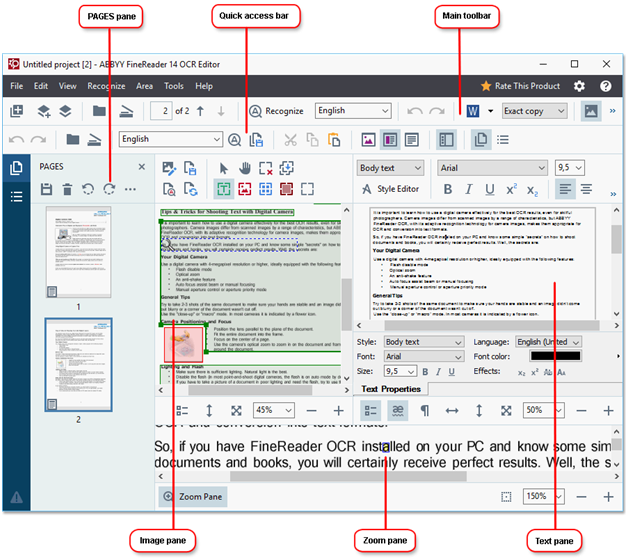
Key features related to text recognition and the ability to extract text from image files or scans include document collation, file comparison, document organizing, annotations, etc. The interface is slick and easy to navigate around, and your OCR jobs can be converted to various output types aside from PDF.
#5 – Adobe Acrobat Pro DC
Acrobat Pro DC has been a market leader since the beginning, and that’s not about to change. However, its interface still leaves a lot to be desired. Many users have said that it is cluttered and that some features are hard to find. Fortunately, that’s not the case with the OCR module, which is very user-friendly and easy to navigate around. There’s a special feature that can scan tables, as well as a document comparison feature to check for variations and similarities.
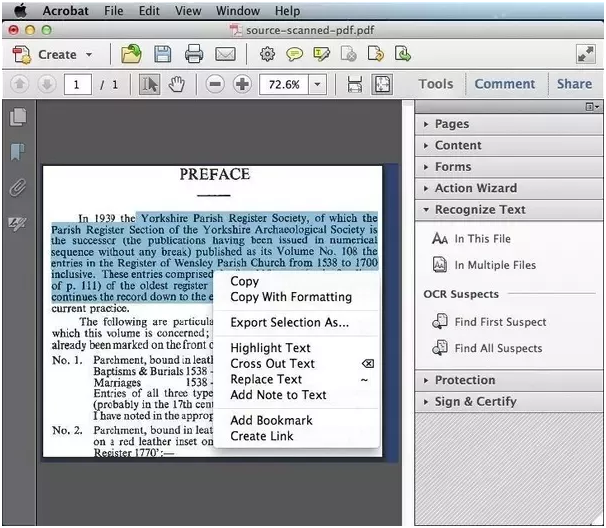
Adobe Acrobat Pro DC is, as the name suggests, well-integrated with the cloud. The Document Cloud makes it easy to share and access documents that multiple users can collaborate on from remote locations. The most compelling aspect is that most business users are likely to be familiar with Acrobat’s interface, which makes it easy to hit the ground running when you want to quickly extract text from image files and scanned documents.
#6 – FreeOCR
As the name suggests, this one’s free to use. But don’t think it’s a lightweight OCR application just because it’s free. It actually uses an open-source text recognition engine called Tesseract, which was developed by none other than HP, the makers of desktops, laptops, and computer peripherals, among other things. Its development has been sponsored by Alphabet Inc. (Google) since 2005, when it went from being a proprietary tool to an open-source conversion engine.
FreeOCR can be used to extract text from an image that’s just been scanned. You also don’t need to select document areas to perform OCR because Tesseract intuitively identifies text blocks and converts them into editable text. It’s a great free tool to have at your disposal, especially if you scan a lot of paper documents for digitization purposes.
#7 – Nanonets
Nanonets is a powerful OCR tool that offers a free plan for up to 100 images. You can extract text from image files like invoices, ID cards, photographs, tax forms, mortgage documents, etc. The tool utilizes deep learning, a branch of artificial intelligence, to spot text and numerals in image files and extracts them into appropriate fields.

This OCR utility also offers API access so you can build the same capabilities into your own application. An upgrade to a paid plan gives you the ability to extract tens of thousands of fields of data, along with faster processing times and other benefits.
#8 – ABBYY Cloud OCR
This is actually the API version of FineReader, also from ABBYY. The API is AI-based and handles a host of features that include text recognition, data extraction, and document conversion.

This is a tool that you can integrate with another application using the REST API. The name suggests that it is also cloud-based, therefore accessible through the web. That makes a powerful combination along with document and workflow management systems.
#9 – OneNote
Many people know that Microsoft is a leader in voice recognition, but few are aware that they’re also great at text recognition. OneNote comes with OCR capabilities and allows you to copy text and extract text from image files. A lot of its ability depends on the legibility and clarity of the image, as is the case with other OCR tools; however, OneNote is surprisingly accurate, only getting the text wrong if it’s virtually unreadable even by a human.
The advantage of using OneNote is that it is a part of Microsoft 365, a holistic cloud-based SaaS offering that is also the most ubiquitous office productivity tool on the planet. If you’re an Office 365 subscriber, you already have access to OneNote OCR.
#10 – Amazon Textract
Amazon Textract is an API tool that uses AI models that are already trained on “tens of millions” of documents from virtually every conceivable industry. Amazon’s reach has allowed this tool to be developed to a razor’s edge, and it is capable of OCR, table extraction, form extraction, and much more.
The pricing is on a pay-per-use basis and starts with a free tier linked to your Amazon Web Services account. It costs about $1.50 for 1,000 pages up to the first 1 million pages and then drops to $0.60 for anything over that. As such, it is ideal for very large workflows where thousands of documents are scanned and archived on a daily basis.
OCR and the Dream of a Paperless World
As far as that dream goes, we’re still dreaming! Physical paper is going to be around for a long time, and the only bridge between paper-based data and digital information is OCR. For that reason, we hope that this showcase of the top 10 tools to extract text from image files, scans, and other document types will help you find the right bridge for your own workflows.


